CUDA_SAR成像实验
一、矩阵转置优化
1、优化前:
__global__ void _gpu_transpose(int A[M][M], int B[M][M])
{
int x = threadIdx.x + blockDim.x * blockIdx.x;
int y = threadIdx.y + blockDim.y * blockIdx.y;
if (x < M && y < M)
{
B[y][x] = A[x][y];
}
}随机生成3000x3000的矩阵进行测试,运行耗时:
Test Passed!
GPU time 116.848 ms
CPU time 533.211 ms2、优化后
采用共享内存进行并行优化
__global__ void _gpu_transpose(int A[M][M], int B[M][M])
{
__shared__ int rafa[TILE_SIZE][TILE_SIZE + 1];
int x = threadIdx.x + blockDim.x * blockIdx.x;
int y = threadIdx.y + blockDim.y * blockIdx.y;
if (x < M && y < M)
{
rafa[threadIdx.y][threadIdx.x] = A[y][x];
}
__syncthreads();
int y2 = threadIdx.y + blockDim.x * blockIdx.x;
int x2 = threadIdx.x + blockDim.y * blockIdx.y;
if (x2 < M && y2 < M)
{
B[y2][x2] = rafa[threadIdx.x][threadIdx.y];
}
}随机生成3000x3000的矩阵进行测试,运行耗时:
Test Passed!
GPU time 17.298 ms
CPU time 522.192 ms二、CUDA中成像实验
该实验为侧视雷达成像实验,验证文献【1】中提出的一种对gpu平台并行优化的成像方案,并探索该成像方案是否适用于前视成像和Jetson平台。
1、实验流程图
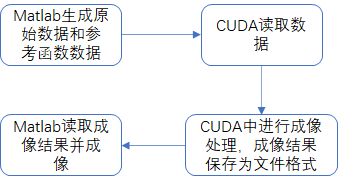
该流程更加符合开题报告中的实验方案
《开题报告》节选

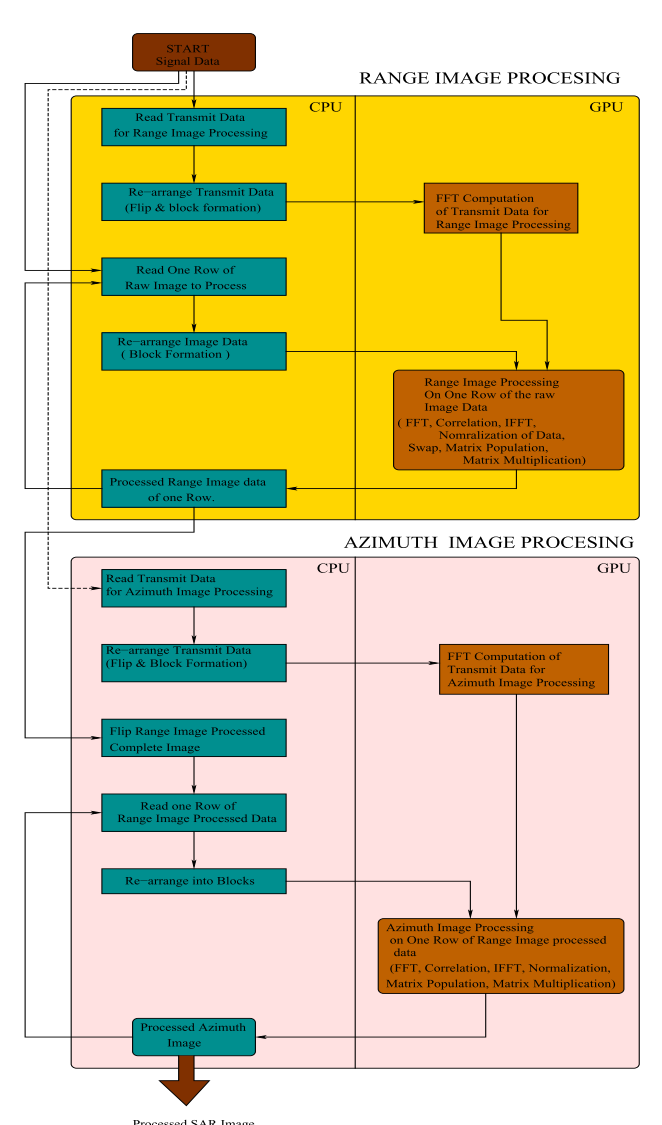
2、算法流程图:
3、成像结果分析
3.1 成像结果:
成像结果和文献中成像结果一致。

文献中的成像结果:
3.2 成像时间
原始数据:
数据来源:RADARSAT-1
原始数据大小:2048x2048 complex doublePC端:
环境:
系统:win11
cpu:AMD 5600X
gpu:Nvidia RTX3070
运行时间:5次测试平均 1740ms
Nano:
环境:Ubuntu 18
运行时间:50000-60000ms
运行差异分析:
nano中的cuda分析工具nvprof出现了一些问题,无法查看kernels和API调用的耗时。但从算法中可以分析,矩阵的翻转操作由cpu处理,因为PC端cpu处理性能远大于nano的处理器性能,所以nano中矩阵翻转的耗时较长。另一方面是该程序在pc端编写,采用内存拷贝的方式进行数据交换,没有针对 nano的统一内存做优化,导致内存拷贝的时间增加。后续会对以上两点做改进,验证该算法在nano中的适用性。
参考文献
[1] Agrawal A K , Bhattacharya C , Somawanshi P , et al. Accelaerated SAR image generation on GPGPU platform. IEEE, 2011.



